We publish a reproducible benchmark of Wolof voice AI.
We benchmark, evaluate, and supply data to frontier labs working on Wolof and French code-switched voice.
104 Senegalese voice samples 6 system configurations Every system above 0.7 mean WER on Wolof speech 23 of 67 numeral tests reveal the dërëm gap
Talking is faster. At high transaction volumes, typing becomes a throughput ceiling.
Wolof is spoken by 12 million people across Senegal, Gambia, and Mauritania, almost always code-switched with French. It is also a language no commercial ASR ships production-ready: every benchmarked system fails on numerals, code-switching, and the silent prompt-echo failure mode we documented.
Frontier labs and voice-product teams shipping Wolof and French code-switched voice come to Kuma for three things: a reproducible benchmark to measure their model against, a curated Wolof corpus tuned for production conditions, and the engineering primitives — wolof-numbers, wolof-ner, dërëm parsing — that fix the failure modes raw ASR cannot.
We constrain outputs, validate numerics, and enforce schema before results reach production systems. WER measures whether you got the words; we measure whether you got the transaction. With structured output and schema validation, the right metric is intent recall — and the gap there is 43% raw vs 73% with our ops layer.
Field-tested. We pitched two Senegalese MFIs in March 2026; both said no. Six weeks of conversation taught us the operator-led wedge wasn't the moat — the lab-grade evaluation work is.
The same number word can mean two different amounts.
Senegalese market merchants quote prices in dërëm without saying the word. "ñaar junni" can mean 2,000 CFA (direct reading) or 2,000 dërëm = 10,000 CFA (implicit-dërëm reading, Guérin 2021 §2.6). There is no universally correct default. Picking one silently is wrong in real systems.
Our parser returns both interpretations and flags the field for human confirmation. This is a core design decision, not a bug.
This is what the Wolof number parser does. Open-sourced on PyPI as wolof-numbers — covers compound forms, genitive constructions, the loanword boundary, and the dërëm convention from 1 to 1 billion. It exists because no commercial ASR resolves any of this on its own. Full treatment in the report (Failure 7).
Sample: a single utterance, the failure, the fix.
Pulled from the 104-sample corpus. Whisper hears the number; the dërëm × 5 conversion never fires. Kuma's parser surfaces both interpretations and asks for confirmation.
alt: 2,000 XOF (direct CFA — confidence 0.4)
needs_confirmation: true
What the benchmark shows
Transcription accuracy, numeral ASR rate, intent top-1 across six system configurations.
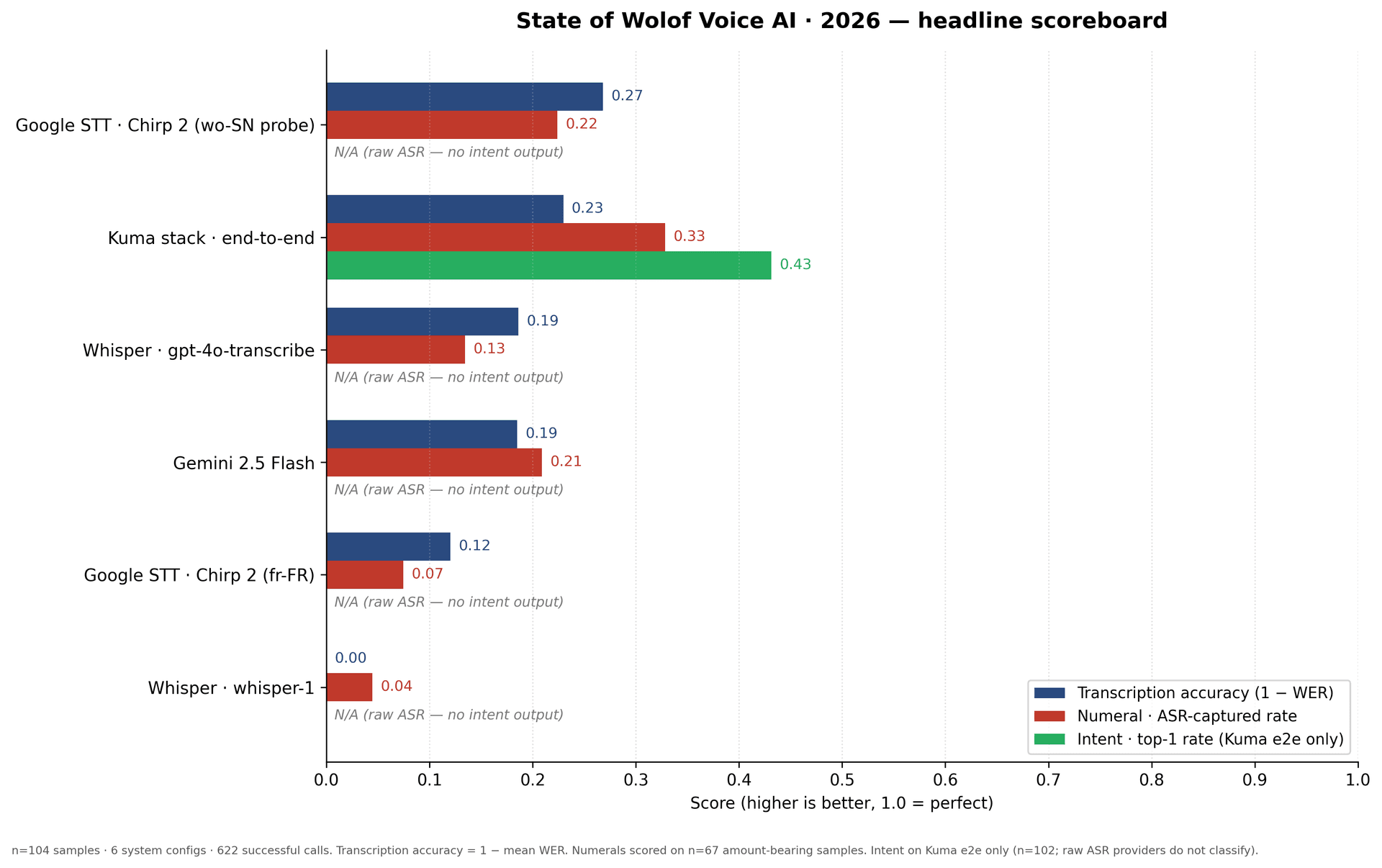
Higher is better on every bar. Kuma end-to-end leads on numeral ASR and intent; raw ASR providers cluster on transcription. Read the methodology in the report →
Specific failures, named.
Every finding in the benchmark cites the model and the failure mode by name.
These failures translate directly into incorrect transaction amounts and broken voice workflows in production.
How to engage.
Two ways to work with us. Prices are published.
We benchmark your ASR, TTS, or LLM against our Wolof + French test set. Comparative report, failure-mode analysis, production-readiness verdict.
Hand-curated Wolof and Bambara voice corpora. Consent-cleared, domain-tuned, delivered with the harness to evaluate them.
Production integration of wolof-numbers, wolof-ner, and our domain dictionaries into operator voice stacks is engaged case-by-case, typically following an evaluation. Provider-agnostic; we work alongside Whisper, Gemini, Chirp, AssemblyAI, Deepgram, or your own ASR. See custom engagements →
Show, don't claim.
Our core components are open-source — use them, fork them, run them on your own data.